Few data challenges are as messy as merging two CRMs after a company acquisition or system consolidation. Two databases, built by different teams with different conventions, get combined — and suddenly the same contacts and companies exist in multiple conflicting versions. Deduplication is the discipline of resolving this. This article lays out a methodology that works for post-merger CRM consolidation.
Why post-merger deduplication is hard
Deduplicating a single CRM is challenging enough; merging two is harder because the duplicates aren’t just accidental repeats — they’re records of the same entities created independently under different conventions, with conflicting data.
The core difficulties are several.
Different formatting conventions — one CRM stored “IBM,” the other “International Business Machines Corp.”
Conflicting field values — the two records show different job titles, phone numbers, or addresses, and you must decide which is correct.
Different data models — the two CRMs may have structured information differently, mapping fields imperfectly.
Volume — merging two large databases produces enormous numbers of potential matches to evaluate.
Relationship preservation — each record carries history (deals, activities, notes) that must survive the merge intact.
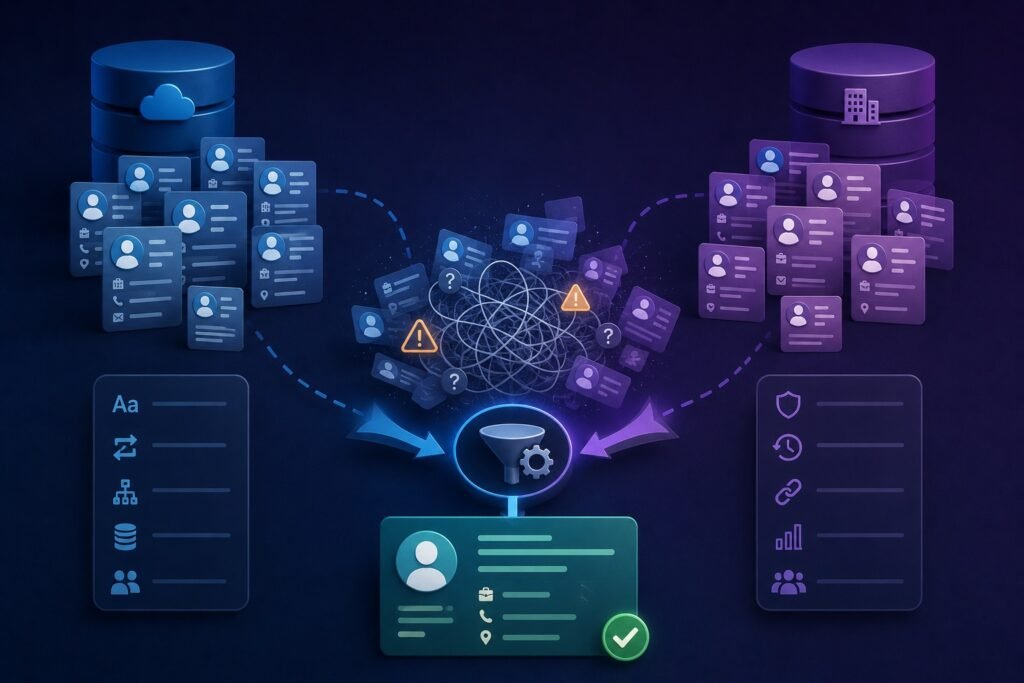
The goal isn’t just removing duplicates — it’s producing a single, accurate, complete record for each real-world entity, preserving the valuable history from both source records. Done carelessly, deduplication destroys data (deleting the wrong duplicate loses its history) or leaves a mess (duplicates survive, conventions clash). A methodical approach is essential.
Common questions
What’s the first step in post-merger CRM deduplication?
Standardization before matching. Before you can identify duplicates accurately, both datasets need consistent formatting — standardized company names, normalized addresses, consistent field structures. Trying to match “IBM” against “International Business Machines Corp” fails until both are normalized. Standardizing first dramatically improves match accuracy in the deduplication step that follows. Skipping standardization produces both missed duplicates (same entity, different formats) and false matches.
How do I decide which duplicate record to keep?
Don’t simply keep one and delete the other — merge them. The goal is a single record combining the best of both: the most recent and accurate field values, and the complete activity history from both sources. Establish rules for field conflicts (e.g., most recently updated value wins, or the source system known to be more accurate for that field wins), and preserve all relationship history (deals, activities, notes) from both records. Merging beats choosing because choosing discards valuable data.
Should deduplication be automated or manual?
A hybrid. High-confidence matches (identical email, exact name-and-company match) can be merged automatically with confidence rules. Lower-confidence potential matches (similar but not identical) need human review, because automated merging of uncertain matches creates errors that are hard to undo. The practical approach is automating the clear cases and queuing the ambiguous ones for human judgment. Fully automated dedup of a messy post-merger dataset risks bad merges; fully manual is impractical at volume.
What matching criteria identify true duplicates?
A combination, weighted by reliability. Email address is the strongest single identifier for contacts (same email almost always means same person). Beyond that, fuzzy matching on name plus company, normalized phone numbers, and standardized addresses build confidence. For companies, domain plus standardized name works well. The key is using multiple criteria together — any single field can mislead, but several aligning (same email, same name, same company) gives high-confidence matches. Set confidence thresholds and treat near-matches cautiously.
How do I avoid destroying data during a merge?
Preserve before you merge. Back up both source databases completely before starting, so any bad merge can be reversed. Merge rather than delete — combine records to retain history from both, rather than keeping one and discarding the other. Log every merge so you have an audit trail. Test the methodology on a sample before running it on the full database. Post-merger deduplication is high-stakes because errors destroy hard-won data; the precautions that prevent destruction are worth the time.
How long does post-merger deduplication take?
It varies with data volume and messiness, but plan for a real project, not a quick task. Standardization, match-rule development, automated processing, human review of ambiguous matches, and validation each take time. A large, messy two-CRM merge can take weeks of careful work. Rushing it produces either destroyed data or surviving duplicates — both expensive. Budget realistic time, and treat it as a structured project with stages rather than a one-pass cleanup.
Can a data provider help with post-merger deduplication?
Yes, in valuable ways. A data provider can standardize both datasets against a common reference, append missing fields to fill gaps before merging, validate which records are still accurate (so you don’t preserve dead data), and bring matching expertise and tooling to the deduplication itself. Matching merged records against an external reference database also helps resolve conflicts — when two records disagree, the current reference data can break the tie. External help is especially valuable for large, messy merges beyond in-house capacity.
How this applies to your business
Standardize before you match — it’s the step that determines everything downstream. Both datasets need consistent company names, normalized addresses, and aligned field structures before deduplication can identify true duplicates accurately. The teams that skip straight to matching get poor results: missed duplicates and false matches alike. Investing in standardization first makes the whole project work.
Merge records rather than choosing between them, and preserve everything first. The value in a post-merger CRM is the combined history from both systems — deals, activities, relationships built over years. Merging to retain the best fields and the full history from both source records preserves that value; deleting one duplicate destroys it. Back up both databases before starting, log every merge, and test on a sample so any error is reversible.
Treat post-merger deduplication as a structured project with external help where the volume or messiness exceeds your in-house capacity. The stakes are high — bad dedup destroys data or leaves chaos — and the work spans standardization, matching, conflict resolution, and validation. A data provider’s standardization, enrichment, validation, and matching capabilities can resolve conflicts and fill gaps that in-house tools can’t, especially for large merges.
Iscope Digital’s
Database Marketing Solutions handle standardization, deduplication, and validation for CRM consolidation, resolving conflicts against the verified
Bizline Direct database. For the ongoing hygiene that keeps a merged CRM clean afterward, see
CRM hygiene: how often should you clean your database? and on quantifying the cost of leaving duplicates unresolved,
Cost of dirty data.

